I en tid hvor store teknologiselskaper konkurrerer om å kontrollere AI-landskapet, er det viktigere enn noensinne å ha alternativer som gir deg full kontroll over dine data. lokalIQ representerer en ny tilnærming til Retrieval-Augmented Generation (RAG) som setter personvern, sikkerhet og kostnadseffektivitet i høysetet.
Hva er lokalIQ?
lokalIQ er et hybrid RAG (Retrieval-Augmented Generation) system som kombinerer vektorsøk med grafdatabaser for å gi intelligent dokumentanalyse og spørsmål-svar funksjonalitet. I motsetning til skybaserte AI-tjenester, kjører lokalIQ fullstendig på din egen infrastruktur og sikrer komplett datapersonvern og kontroll.
Hvorfor velge lokal RAG?
🔒 Sikkerhet og personvern
Terminalgrensesnitt vs. nettleser: I motsetning til de fleste AI-tjenester som utelukkende kjører i nettleseren, hvor både nettleserleverandør (google, microsoft) og nettleserutvidelser kan og vil samle sensitiv informasjon, kan lokalIQ benytte terminalgrensesnitt. Dine data forblir i et kontrollert miljø som reduserer risikoen for tilsiktede og utilsiktede data-lekasjer og mot at informasjonen din blir videresolgt til tredjepart.
Fullstendig kontroll: Alle dokumenter, samtaler og AI-interaksjoner forblir lokalt på din maskin. Ingen data sendes til eksterne servere, og du beholder full kontroll over hvem som har tilgang til informasjonen.
Ingen eksterne avhengigheter: Du kan være trygg på at dine data ikke blir brukt til å trene språkmotorene fra Meta, OpenAI, Microsft, Google, Grok, Apple og Amazon med flere. I den grad systemet krever mer datakraft enn lokal server kan tilby kan systemet konfigureres til å benytte Franske Mistral som er underderlagt GDPR lovgivning i Norge og EU.
💰 Kostnadseffektivitet
Lokale LLM: Ved å bruke lokale språkmotorer kan du kjøre kraftige språkmodeller som Llama 3.2 på din egen maskinvare [2]. Du betaler ingen lisenser og du har ingen "per-token" kostnader - bare en engangsutgift for oppsett og konfigurering [3].
Valgfri sky-lagring: All prosessering og lagring av data kan skje lokalt, du slipper kostnadene knyttet til å sende store mengder data frem og tilbake til sky-tjenester [4].
Skalerbar, og etter ditt budsjett: Start med det du har og oppgrader maskinvaren etter behov. Ingen tvungne enterprise-pakker eller uforutsigbare kostnader basert på bruk.
🏢 Enterprise-fordeler
Compliance og regulering: For organisasjoner som må overholde GDPR, Schrems II, eller andre databeskyttelsesreguleringer, eliminerer lokal prosessering mange compliance-utfordringer. Data forlater aldri din jurisdiksjon.
Luftgap-sikkerhet: Systemet kan kjøres helt frakoblet fra internett, noe som gjør det ideelt for høysikkerhetsmiljøer som forsvarsindustri, finans eller kritisk infrastruktur.
Tilpassing uten begrensninger: Du kan tilpasse systemet helt etter dine behov uten å være avhengig av eksterne leverandørers API-endringer eller servicebegrensninger.
🚀 Tekniske fordeler
Høy ytelse: Med GPU-akselerasjon og optimalisert chunking kan lokale systemer overgå sky-baserte løsninger for spesifikke bruksområder [5].
Offline-tilgang: Systemet fungerer uten internettforbindelse, noe som gjør det perfekt for felt-arbeid, reise eller ustabile nettverksmiljøer.
Flerspråklig støtte: Bygget med norsk og andre språk i tankene, med mulighet for å finjustere modeller på dine spesifikke behov.
| Framtiden er lokal! Ta kontroll over dine data. |
Kjerneteknologi
🧠 AI og Maskinlæring
- LLM-integrasjon: Støtter flere leverandører (Ollama, OpenAI, Mistral, Anthropic, Google Gemini)
- Lokale modeller: Kjører Llama, Mistral og andre modeller lokalt via Ollama
- Embeddings: HuggingFace flerspråklige modeller for semantisk forståelse
- Entitetsutvinning: Skjemabasert utvinning med svartelistefiltrering for rene kunnskapsgrafer
- Spørreklassifisering: Dedikert LLM velger automatisk optimal gjenfinningsstrategi per spørsmål
🗄️ Hybrid Database-arkitektur
Vektor-lager
- ChromaDB: Filbasert vektordatabase for semantisk likhetssøk (standard)
- pgvector: PostgreSQL vektorsøk for større dokumentmengder
Graf-lager
- Neo4j: Anbefalt grafdatabase med fler-instans arkitektur (én instans per prosjekt)
- Apache AGE: PostgreSQL graf-utvidelse for multi-tenant med automatisert oppsett
- FalkorDB: Legacy Redis-basert grafdatabase (avviklet)
Integrasjon
- PropertyGraphStore: LlamaIndex integrasjonslag som kombinerer vektor- og graftilnærminger
- Dobbeltlagring: Dokumenter lagres som både vektorer og kunnskapsgrafer
📖 Avansert dokumentbehandling
Docling-integrasjon (lisensbaserte funksjoner)
- Gratis Nivå: PDF, DOCX, Excel, HTML-parsing med grunnleggende tabellutvinning (70% nøyaktighet)
- Premium Nivå: TableFormer for høy-nøyaktige tabeller (95-98%) - kritisk for finansrapporter
- Bedrift Nivå: OCR, lydtranskripsjon, vision-language modeller for bildeforståelse
Behandlingsprosess
- Flerfomatstøtte: PDF, DOCX, CSV, Excel, Markdown, HTML, ODT, JSON, ren tekst
- Semantisk oppdeling: Kontekstbevisst dokumentoppdeling (bevarer entitetskoherens)
- Deduplikasjon: Intelligent innholdsdeduplikasjon på tvers av dokumenter
- Parallell prosessering: Samtidig embedding-generering og entitetsutvinning
- Forbehandlingskommando: iq preprocess konverterer komplekse dokumenter til ren Markdown
🔍 Intelligent gjenfinning
Tre-stegs strategi for hybridsøk
- Vektorlikhet: Semantisk embedding-basert gjenfinning
- Kunnskapsgraf: Entitet-relasjonstraversering
- BM25 Fulltekst: Tradisjonelt nøkkelord-søk
Avanserte funksjoner
- Spørreklassifisering: LLM-basert ruter velger optimal strategi (BM25_FAVOR, KG_FAVOR, VECTOR_FAVOR, HYBRID_DEFAULT)
- Query Fusion: Flere søkestrategier fusjonert med reciprocal rank fusion
- Dokumenttype-Forsterkning: Automatisk spørrebasert dokumenttype-deteksjon og score-forsterkning
- Reranking: Cross-encoder modeller for endelig relevansscoring
- Adaptive parametere: Spørrespesifikk optimalisering
💬 Samtalehukommelse
- Fler-Omgangs Samtaler: Naturlige oppfølgingsspørsmål (“Hva mer?”, “Kan du utdype?”)
- Kontekstuell Forståelse: Håndterer pronomen og referanser til tidligere spørsmål
- Flere Formatstiler: Dialog, sammendrag eller strukturert samtalehistorikk
- Konfigurerbart: Omgangstelling, token-budsjett, relevansfiltrering, auto-utløp
⚙️ Konfigurasjonssystem
- Pydantic-modeller: Typesikker konfigurasjon med kjøretidsvalidering
- YAML-komposisjon: Menneskelesbar med arvstøtte
- Lisenshåndtering: Funksjonsporter for premiumfunksjoner
- Flerprosjektstøtte: Spør på tvers av flere kunnskapsbaser med vektet fusjon
Brukergrensesnitt
🖥️ Kommandolinje (CLI)
- Moderne Kommandoer: ingest, query, preprocess, postgres setup, status, diagnose
- Automatiseringsklart: Perfekt for skript, CI/CD-pipelines, planlagte oppgaver
- PostgreSQL Oppsett: Automatisert database/bruker-oppretting for Apache AGE (iq postgres setup)
📺 Terminal brukergrensesnitt (TUI)
- Rikt Interaktivt Grensesnitt: Ved bruk av Textual-rammeverket
- Sanntids Chat: Live svar med syntaksutheving
- Flerpanel: Chat, konfigurasjon, debugging, entitetsvisning
- Slash-Kommandoer: /help, /clear, /write, /url
- Eksport: Markdown, ren tekst, Word, PDF formater
🌐 Webgrensesnitt
Chatopplevelse
- WebSocket Streaming: Sanntids responsstreaming
- Kommandohistorikk: Naviger tidligere spørsmål med piltaster
- Sesjonsbehandling: Vedvarende samtaler på tvers av sideoppdateringer
- Slash-Kommandoer: /help, /clear, /write, /url, /config
Prosjekthåndtering
- Dyp Mappenavigering: Bla gjennom hierarkiske prosjektstrukturer med breadcrumbs
- Visuell Differensiering: Mapper (rav) vs. konfigurasjonsfiler (indigo)
- Konfigurasjonsforhåndsvisning: Se prosjektinnstillinger før valg
Avanserte visualiseringer
- Mermaid-Diagrammer: Automatisk syntaksfiksing og gjengivelse
- Eksporter til SVG (vektor), PNG (høyoppløselig), eller skriv ut/PDF
- Håndterer norske tegn og komplekse etiketter
- Tabeller: Forbedret gjengivelse fra Docling-forbehandling med TableFormer-nøyaktighet
- Diagrammer: Plotly.js integrasjon for søylediagrammer,
linjediagrammer, kakediagrammer
- Interaktiv sveip, zoom, pan
- Norske etiketter og formatering
Eksportfunksjoner
- Samtaleeksport: Markdown, ren tekst, HTML, PDF (via utskrift), Word
- Mermaid-Diagrammer: Individuell diagrameksport (SVG/PNG/PDF)
- Utskriftsoptimalisert CSS: Ren, profesjonell PDF-utdata fra nettleserutskrift
Nøkkeldifferensiatorer
🔒 Komplett personvern
- Ingen Skyavhengighet: Alt kjører på dine servere
- GDPR-kompatibel: Ingen data forlater din infrastruktur
- Offline-kapabel: Fungerer uten internettforbindelse
- Multi-tenant-Isolasjon: Database-per-kunde eller fler-instans arkitektur
💰 Kostnadseffektiv
- Faste Kostnader: Engangs maskinvareinvestering vs. løpende API-avgifter
- Dual-LLM Arkitektur: Lokale modeller for bakgrunnsbehandling, valgfri sky for spørsmål
- Skalerbar: Legg til kapasitet uten per-spørsmål kostnader
- Kostnadsoptimalisering: Separate LLM-er for spørsmål vs. entitetsutvinning
🇳🇴 Optimalisert for norsk språk
- Språkstøtte: Norske embeddings, prompts og finansterminologi
- Entitetstyper: Norsk-spesifikke entiteter (kommuner, fylker, budsjettpost, etc.)
- Tegnhåndtering: Automatisk Æ/Ø/Å konvertering for databasekompatibilitet
- Domenefokus: Spesialisert for norsk offentlig sektor, helsevesen og finans
🔧 Svært konfigurerbart
- Alt er konfigurerbart: Chunk-størrelser, gjenfinningsparametere, modellvalg, forsterknigsfaktorer
- Leverandøragnostisk: Bytt mellom LLM-leverandører enkelt
- Ytelsesjustering: Individuell gjenfinningskontroll (vector_top_k, graph_top_k)
- Spørrestrategier: Flere klassifiseringskategorier med tilpassede prompts
🚀 Produksjonsklare funksjoner
- Entitetssvartelistefiltrering: Blokkerer søppeltyper mens LLM-oppdagelse tillates
- Timeout-Håndtering: Hierarkisk validering forhindrer utvinnigsfeil
- Minnehåndtering: GPU cache-rydding, token-budsjetthåndtering
- Diagnostiske Verktøy: Entitetsanalyse, relasjonsinspeksjon, grafstatistikk
- Automatisert Oppsett: iq postgres setup for Apache AGE-initialisering
Teknisk arkitektur
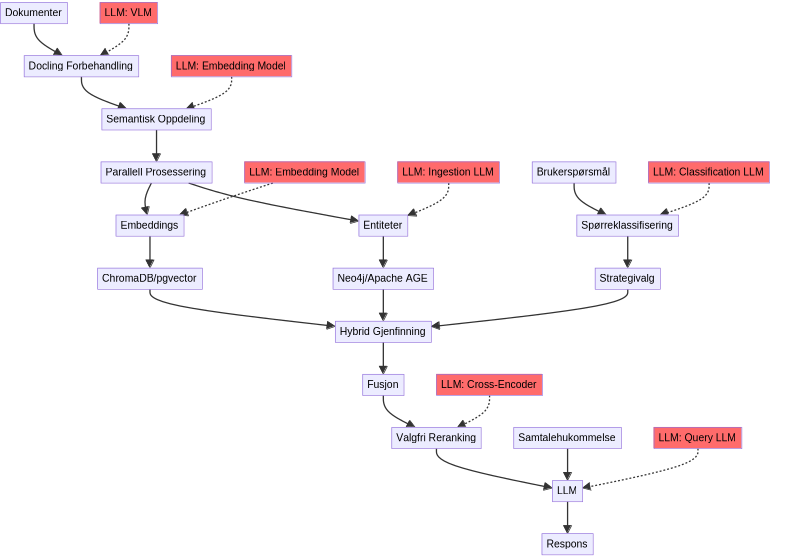
Ytelseskarakteristikker
- Ingesting: Behandler tusenvis av dokumenter med deduplikasjon og entitetsutvinning
- Spørrehastighet: 200ms-2s avhengig av kompleksitet, maskinvare og gjenfinningsstrategi
- Skalerbarhet: Håndterer bedriftsdokumentsamlinger (testet med 800+ siders pdf dokumenter)
- Minneeffektiv: Smart chunking, batch-behandling, GPU-minnehåndtering
- Klassifisering: <100ms spørreklassifisering med lokal LLM
Brukstilfeller
🏥 Helsevesen
- Pasientjournalanalyse (GDPR-kompatibel)
- Medisinsk beslutningsstøtte
- Forskningsdokumentbehandling
- Helseplattformen-dokumentasjonsanalyse
🏛️ Offentlig sektor
- Kommunal dokumentanalyse (årsregnskaper, budsjett)
- Kommunestyremøtereferatanalyse
- Politisk forskning og compliance-sjekking
- Innbyggertjenesteautomatisering
🏢 Bedrift
- Interne kunnskapsbaser
- Kontrakt- og juridisk dokumentanalyse
- Finansrapportanalyse med komplekse tabeller
- Kundesupportautomatisering
📊 Finansielle tjenester
- Årsregnskapsanalyse med TableFormer-nøyaktighet
- Budsjettdokumentbehandling
- Investeringsdokumentasjon
- Økonomisk indikatorsporing
Sammendrag
lokalIQ representerer en ny generasjon AI-drevne dokumentanalysesystemer som prioriterer personvern, kostnadseffektivitet og ytelse. Ved å kombinere de nyeste fremskrittene innen vektorsøk, kunnskapsgrafer og spørreklassifisering med lokale AI-modeller, gir det bedriftsklare funksjoner uten personvernbekymringene og løpende kostnadene ved skybaserte løsninger.
lokalIQ = Vektorsøk + Graf-Intelligens + Spørreklassifisering + Dokumentforsterkning + Samtalehukommelse + Lokal AI + Komplett Personvern
noter
| [1] | lokalt som i at systemet ikke har noen eksterne avhengigheter. |
| [2] | Maskinvare iht til spesifikasjon kan leies eller eies av kunde |
| [3] | Vi tilbyr valgfri årlig vedlikehold- og utviklingsavtale. |
| [4] | De fleste sky-tjenester støttes for data-lagring, også vektor og kunnskapsgrafer. |
| [5] | avhengig av datamengde. |